Configuring the transcript
So far you should know
- How to connect and authenticate to the Speechmatics Batch SaaS
- How to successfully submit a media file for processing
- How to check the status of one or multiple jobs
- How to retrieve the transcript, and interpret the output
The following section will show you how to configure your requests to take advantage of Speechmatics features.
Important note on examples
All examples below show the configuration separately to the actual HTTP Submission request. This configuration can be enclosed within a file (e.g. config.json). How to submit this configuration file as part of a successful job request is shown for both Linux and Windows. Examples for Windows should work in both CMD mode and Powershell.
Fetch URL
Speechmatics Batch SaaS Demo: Fetch URL Callback
Examples so far have shown to submit a job where a media file is locally uploaded. If you store your digital media in cloud storage (for example AWS S3 or Azure Blob Storage) you can also submit a job by providing the URL of the audio file. The configuration uses a fetch_data section, which looks like this:
Configuration example
{
"type": "transcription",
"transcription_config": {
"language": "en",
"diarization": "speaker"
},
"fetch_data": {
"url": "${URL}/{FILENAME}"
}
}
Fetch failure
If the Speechmatics Batch SaaS is unable to retrieve audio from the specified online location, the job will fail, with a status of rejected, and no transcript will be generated. Users can now retrieve failure information by making a GET /jobs/$JOBID request, and use that to carry out diagnostic information.
If the job has failed, there will be an additional errors element, which will show all failure messages Speechmatics Batch SaaS encountered when carrying out the fetch request. Please note, there can be multiple failure attempts associated with one submitted job, as there is a retry mechanism in place.
{
"job": {
"config": {
"fetch_data": {
"url": "https://example.com/average-files/punctuation1.mp3"
},
"notification_config": [
{
"contents": [
"jobinfo"
],
"url": "https://example.com/"
}
],
"transcription_config": {
"language": "de"
},
"type": "transcription"
},
"created_at": "2021-07-19T12:55:03.754Z",
"data_name": "",
"duration": 0,
"errors": [
{
"message": "unable to fetch audio: http status code 404",
"timestamp": "2021-07-19T12:55:05.425Z"
},
{
"message": "unable to fetch audio: http status code 404",
"timestamp": "2021-07-19T12:55:07.649Z"
},
{
"message": "unable to fetch audio: http status code 404",
"timestamp": "2021-07-19T12:55:17.665Z"
},
{
"message": "unable to fetch audio: http status code 404",
"timestamp": "2021-07-19T12:55:37.643Z"
}
],
"id": "a81ko4eqjl",
"status": "rejected"
}
}
Unix/Ubuntu example
curl -L -X POST https://asr.api.speechmatics.com/v2/jobs/ -H "Authorization: Bearer NDFjOTE3NGEtOWVm" -F config="$(cat config.json)"
Windows example
curl.exe -L -X POST https://asr.api.speechmatics.com/v2/jobs/ -H "Authorization: Bearer NDFjOTE3NGEtOWVm" -F config="<config.json"
Some cloud storage solutions may require authentication. You can use the auth_headers property in the fetch_data section to provide the headers necessary to access the resource.
Ensure that any URLs you generate - for example using AWS pre-signed URLs or Microsoft Azure Shared Access Signatures - have not expired, or the job will be rejected.
Speaker separation (Diarization)
Speechmatics offers four different modes for separating out different speakers in the audio:
| Type | Description | Use Case |
|---|---|---|
| speaker diarization | Aggregates all audio channels into a single stream for processing and picks out unique speakers based on acoustic matching. | Used in cases where there are multiple speakers embedded in the same audio recording and it's required to understand what each unique speaker said. |
| channel diarization | Transcribes each audio channel separately and treats each channel as a unique speaker. | Used when it's possible to record each speaker on separate audio channels. |
| speaker change (beta) | Provides the point in transcription when there is believed to be a new speaker. | Used for when you just need to know the speaker has changed usually in a real-time application. |
| channel diarization & speaker change | Transcribes each audio channel separately and within each channel provides the point when there is believed to be a new speaker. | Used when it's possible to record some speakers on a separate audio channel, but some channels there are multiple speakers. |
Each of these modes can be enabled by using the diarization config. The following are valid values:
The default value is none - e.g. the transcript will not be diarized.
| Type | Config Value |
|---|---|
| speaker diarization | speaker |
| channel diarization | channel |
| speaker change | speaker_change |
| channel diarization & speaker change | channel_and_speaker_change |
Speaker diarization
Speaker diarization aggregates all audio channels into a single stream for processing, and picks out different speakers based on acoustic matching.
By default the feature is disabled. To enable speaker diarization the following must be set when you are using the config object:
{
"type": "transcription",
"transcription_config": {
"language": "en",
"diarization": "speaker"
}
}
When enabled, every word and punctuation object in the output results will be a given "speaker" property which is a label
indicating who said that word. There are two kinds of labels you will see:
S#- S stands for speaker and the # will be an incrementing integer identifying an individual speaker. S1 will appear first in the results, followed by S2 and S3 etc.UU- Diarization is disabled or individual speakers cannot be identified.UUcan appear for example if some background noise is transcribed as speech, but the diarization system does not recognise it as a speaker.
Note: Enabling diarization increases the amount of time taken to transcribe an audio file. In general we expect diarization to take roughly the same amount of time as transcription does, therefore expect the use of diarization to roughly double the overall processing time.
The example below shows relevant parts of a transcript with 3 speakers. The output shows the configuration information passed in the config.json object and relevant segments with the different speakers in the JSON output. Only part of the transcript is shown here to highlight how different speakers are displayed in the output.
"format": "2.8",
"metadata": {
"created_at": "2020-07-01T13:26:48.467Z",
"type": "transcription",
"language_pack_info": {
"adapted": false,
"itn": true,
"language_description": "English",
"word_delimiter": " ",
"writing_direction": "left-to-right"
},
"transcription_config": {
"language": "en",
"diarization": "speaker"
}
},
"results": [
{
"alternatives": [
{
"confidence": 0.93,
"content": "hello",
"language": "en",
"speaker": "S1"
}
],
"end_time": 0.51,
"start_time": 0.36,
"type": "word"
},
{
"alternatives": [
{
"confidence": 1.0,
"content": "hi",
"language": "en",
"speaker": "S2"
}
],
"end_time": 12.6,
"start_time": 12.27,
"type": "word"
},
{
"alternatives": [
{
"confidence": 1.0,
"content": "good",
"language": "en",
"speaker": "S3"
}
],
"end_time": 80.63,
"start_time": 80.48,
"type": "word"
}
In our JSON output, start_time identifies when a person starts speaking each utterance and end_time identifies when they finish speaking.
Speaker diarization tuning
The sensitivity of the speaker detection is set to a sensible default that gives the optimum performance under most circumstances. However, you can change this value based on your specific requirements by using the speaker_sensitivity setting in the speaker_diarization_config section of the job config object, which takes a value between 0 and 1 (the default is 0.5). A higher sensitivity will increase the likelihood of more unique speakers returning. For example, if you see fewer speakers returned than expected, you can try increasing the sensitivity value, or if too many speakers are returned try reducing this value. It's not guaranteed to change since several factors can affect the number of speakers detected. Here's an example of how to set the value:
{
"type": "transcription",
"transcription_config": {
"language": "en",
"diarization": "speaker",
"speaker_diarization_config": {
"speaker_sensitivity": 0.6
}
}
}
Speaker diarization post-processing
To enhance the accuracy of our speaker diarization, we make small corrections to the speaker labels based on the punctuation in the transcript. For example if our system originally thought that 9 words in a sentence were spoken by speaker S1, and only 1 word by speaker S2, we will correct the incongruous S2 label to be S1. This only works if punctuation is enabled in the transcript.
Therefore if you disable punctuation, for example by removing all permitted_marks in the punctuation_overrides section
of the config.json then expect the accuracy of speaker diarization to vary slightly.
Speaker diarization timeout
Speaker diarization will timeout if it takes too long to run for a particular audio file. Currently the timeout is set to 5 minutes or 0.5 * the audio duration; whichever is longer. For example, with a 2 hour audio file the timeout is 1 hour. If a timeout happens the transcript will still be returned but without the speaker labels set.
If a timeout occurs then all speaker labels in the output will be labelled as UU.
Under normal operation we do not expect diarization to timeout, but diarzation can be affected by a number of factors including audio quality and the number of speakers. If you do encounter timeouts frequently then please get in contact with Speechmatics support.
Channel diarization
The V2 API also supports Channel diarization which can be used to add your own speaker or channel labels to the transcript. With Channel diarization, multiple input channels are processed individually and collated into a single transcript. In order to use this method of diarization your input audio must have been transcoded into multiple channels or streams.
In order to use this feature you set the diarization property to channel. You optionally name these channels by using the channel_diarization_labels in the configuration:
{
"type": "transcription",
"transcription_config": {
"language": "en",
"diarization": "channel",
"channel_diarization_labels": [
"Presenter",
"Questions"
]
}
}
If you do not specify any labels then defaults will be used (e.g. Channel 1). The number of labels you use should be the same as the number of channels in your audio. Additional labels are ignored. When the transcript is returned a channel property for each word will indicate the speaker, for example:
"results": [
{
"type": "word",
"end_time": 1.8,
"start_time": 1.45,
"channel": "Presenter",
"alternatives": [
{
"display": {
"direction": "ltr"
},
"language": "en",
"content": "world",
"confidence": 0.76
}
]
}
]
Speaker change detection
This feature introduces markers into the JSON transcript only that indicate when a speaker change has been detected in the audio. For example, if the audio contains two people speaking to each other and you want the transcript to show when there is a change of speaker, specify speaker_change as the diarization setting:
{
"type": "transcription",
"transcription_config": {
"language": "en",
"diarization": "speaker_change"
}
}
The transcript will have special json elements in the results array between two words where a different person started talking. For example, if one person says "Hello James" and the other responds with "Hi", there will a speaker_change json element between "James" and "Hi".
"results": [
{
"start_time": 0.1,
"end_time": 0.22,
"type": "word",
"alternatives": [
{
"confidence": 0.71,
"content": "Hello",
"language": "en",
"speaker": "UU"
}
]
},
{
"start_time": 0.22,
"end_time": 0.55,
"type": "word",
"alternatives": [
{
"confidence": 0.71,
"content": "James",
"language": "en",
"speaker": "UU"
}
]
},
{
"start_time": 0.55,
"end_time": 0.55,
"type": "speaker_change",
"alternatives": []
},
{
"start_time": 0.56,
"end_time": 0.61,
"type": "word",
"alternatives": [
{
"confidence": 0.71,
"content": "Hi",
"language": "en",
"speaker": "UU"
}
]
}
]
The sensitivity of the speaker change detection is set to a sensible default that gives the optimum performance under most circumstances. You can however change this if you with using the speaker_change_sensitivity setting, which takes a value between 0 and 1 (the default is 0.4). The higher the sensitivity setting, the more likelihood of a speaker change being indicated. We've found through our own experimentation that values outside the range 0.3-0.6 produce too few speaker change events, or too many false positives. Here's an example of how to set the value:
{
"type": "transcription",
"transcription_config": {
"language": "en",
"diarization": "speaker_change",
"speaker_change_sensitivity": 0.55
}
}
Speaker change detection With Channel diarization
The speaker change feature can be used in conjunction with channel diarization. It will process the channels separately and indicate in the output both the channels and the speaker changes. For example, if a two-channel audio contains two people greeting each other (both recorded over the same channel), the config submitted with the audio can request speaker change detection like this:
{
"type": "transcription",
"transcription_config": {
"diarization": "channel_and_speaker_change"
}
}
Again, the speaker_change_sensitivity setting may be used to tune the likelihood of speaker change being identified.
Custom dictionary
The Custom Dictionary feature allows a list of custom words to be added for each transcription job. This helps when a specific word is not recognised during transcription. It could be that it's not in the vocabulary for that language, for example a company or person's name. Adding custom words can improve the likelihood they will be output.
The sounds_like feature is an extension to this to allow alternative pronunciations to be specified to aid recognition when the pronunciation is not obvious.
The Custom Dictionary feature can be accessed through the additional_vocab property.
Prior to using this feature, consider the following:
sounds_likeis an optional setting recommended when the pronunciation is not obvious for the word or it can be pronounced in multiple ways; it is valid just to provide thecontentvaluesounds_likeonly works with the main script for that language- Japanese (ja)
sounds_likeonly supports full width Hiragana or Katakana
- Japanese (ja)
- You can specify up to 1000 words or phrases (per job) in your custom dictionary
"transcription_config": {
"language": "en",
"additional_vocab": [
{
"content": "gnocchi",
"sounds_like": [
"nyohki",
"nokey",
"nochi"
]
},
{
"content": "CEO",
"sounds_like": [
"C.E.O."
]
},
{
"content": "financial crisis"
}
]
}
In the above example, the words gnocchi and CEO have pronunciations applied to them; the phrase financial crisis does not require a pronunciation. The content property represents how you want the word to be output in the transcript.
Output locale
For the English language pack only, it is possible to specify the spelling rules to be used when generating the transcription, based on the output_locale configuration setting.
The three locales that are available are:
- British English (en-GB)
- US English (en-US)
- Australian English (en-AU)
If no locale is specified then the ASR engine will use whatever spelling it has learnt as part of our language model training (in other words it will be based on the training data used).
An example configuration request is below:
{
"type": "transcription",
"transcription_config": {
"language": "en",
"output_locale": "en-GB"
}
}
The following locales are supported for Chinese Mandarin:
- Simplified Mandarin (cmn-Hans)
- Traditional Mandarin (cmn-Hant)
The default is Simplified Mandarin.
Advanced punctuation
All Speechmatics language packs support Advanced Punctuation. This uses machine learning techniques to add in more naturalistic punctuation, improving the readability of your transcripts.
The following punctuation marks are supported for each language:
| Language(s) | Supported Punctuation | Comment |
|---|---|---|
| Cantonese, Mandarin | , 。 ? ! 、 | Full-width punctuation supported |
| Japanese | 。 、 | Full-width punctuation supported |
| Hindi | । ? , ! | |
| All other languages | . , ! ? |
If you do not want to see any of the supported punctuation marks in the output, then you can explicitly control this through the punctuation_overrides settings, for example:
"transcription_config": {
"language": "en",
"punctuation_overrides": {
"permitted_marks":[ ".", "," ]
}
}
This will exclude exclamation and question marks from the returned transcript.
All Speechmatics output formats support Advanced Punctuation. JSON output places punctuation marks in the results list marked with a type of "punctuation".
Note: Disabling punctuation may slightly harm the accuracy of speaker diarization. Please see the "Speaker diarization post-processing" section in these docs for more information.
Notifications
Notifications allow users to be informed both as to the status of a job and to receive the output, without having to continuously poll the Speechmatics Batch SaaS to check for the status of a job.
Speechmatics sends a notification to a web service that you control and specify in the configuration request. This is done once the job is done transcript is available.
Notification call flow
The call flow for the notification method looks like this:
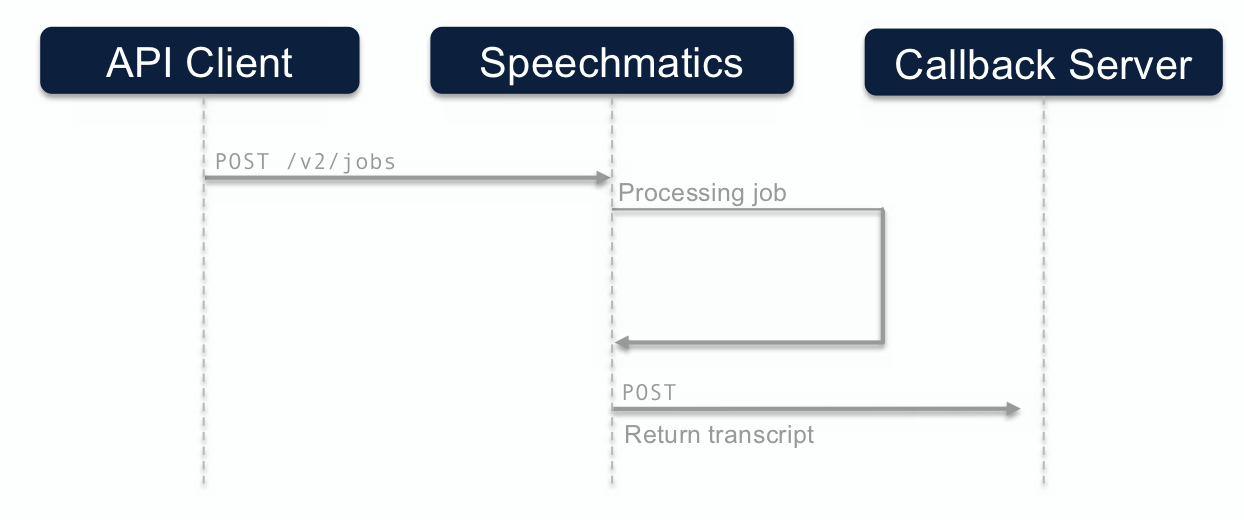
Below are examples of a configuration that requests a JSON-v2 transcript and the media file upon job completion:
Notification configuration example
{
"type": "transcription",
"transcription_config": {
"language": "en"
},
"notification_config": [
{
"url": "https://collector.example.org/callback",
"contents": [
"transcript",
"data"
],
"auth_headers": [
"Authorization: Bearer eyJ0eXAiOiJKV1QiLCJhb"
]
}
]
}
This configuration example assumes you have implemented a /callback endpoint on host collector.example.org that listens for POST requests containing Speechmatics transcripts. In this example requests are only accepted if the auth token eyJ0eXAiOiJKV1QiLCJhb is used (note this is the auth token that your service accepts, not the Speechmatics auth token).
How to configure a notification
Here is the relevant information you can pass in a notification request:
| Option | Mandatory | Description |
|---|---|---|
| URL | Yes | The web address where the notification will be sent. Up to 3xURLs are supported |
| auth_headers | no | If required to successfully authenticate to your specificed notification location |
| Content | No | There are multiple types of content that can be sent. Multiple attachments can be sent in multiple callbacks: transcript: The transcript in json-v2 format transcript.json-v2: The transcript in json-v2 format transcript.txt: The Transcript in txt format transcript.srt: The transcript in srt format data: The media file provided in the job submission request jobinfo: The configuration information used to submit the job. Also present in the transcript in json-v2 format |
| Method | No | POST and PUT HTTP Methods are supported. If none is specified, then POST is used |
Further Notes:
- If no content is requested as part of the notification, it will simply be a HTTP message containing the job ID and the status of the job
- Up to 3 URLs are supported in any request
- Multiple pieces of content can be sent as multiple attachments in one request, allowing any combination of the input(s) and output(s) of the job to be forwarded to another processing stage.
- You can setup multiple notifications to different endpoints: for instance you can send a jobinfo notification to one service, and the transcript notification to another.
- Callbacks with a single attachment will send the content item as the HTTP request body, rather than using multipart mode. This allows writing an individual item to an object store like Amazon S3.
auth_headersshould be specified:- To satisfy authentication / authorization requirements for systems that do not support auth tokens in query parameters.
- To control behaviour of an object store or another existing service endpoint.
- Multiple callbacks can be specified per job.
- This allows sending individual pieces of content to different URLs, eg. to allow uploading the audio and transcript to an object store as distinct objects for a downstream workflow.
- It allows sending arbitrary combinations of the inputs/outputs to multiple destinations, to support a fanout workflow.
Callbacks will be invoked in parallel and so may complete in any order. If a downstream workflow depends on getting several items of content delivered as separate callbacks (eg. uploaded as separate items to S3), then the downstream processing logic will need to be robust to the ordering of uploads and the possibility that only some might succeed.
To ensure that the callbacks you receive come from Speechmatics you can apply an allowlist.
Accepting the notification
You need to ensure that the service that you implement to receive the callback notification is capable of processing the Speechmatics transcript using the format that has been specified in the config JSON. When testing your integration you should check the error logs on your web service to ensure that notifications are being accepted and processed correctly.
The callback appends the job ID as a query string parameter with name id, as well as the status of the job. As an example, if the job ID is r6sr3jlzjj, you'd see the following POST request:
POST /callback?id=r6sr3jlzjj&status=success HTTP/1.1
Host: collector.example.org
The user agent is Speechmatics-API/2.0.
Notification webserver configuration
Once the submitted media file is transcribed, and the transcript file is available, the Speechmatics cloud service will send the transcript file in a HTTP POST request to the client web server (customers webserver) specified in the notification_config config object. If the Speechmatics cloud service does not receive a 2xx response (that the request is successfully received, understood, or accepted) it will keep trying to send the file until it reaches the set timeout threshold.
If the clients webserver that has been set as the callback endpoint is not configured with a large enough size limit to receive the transcript file and original media file it will generate a 413 (Request Entity Too Large) response to the Speechmatics service. The Speechmatics cloud service app has not receive a 2xx response it will continue to retry sending the file.
Users are recommended to check their webserver size limits to ensure they are adequate for the files that will be sent.
Notification failure
If the Speechmatics cloud service is unable to send a notification to the specified online location, the transcript is still available to directly retrieve via an API request. A user can retrieve failure information by making a GET /jobs/$JOBID request.
If the job has failed, there will be an additional errors element, which will show all failure messages Speechmatics cloud service encountered when attempting to send notifications. Please note, there can be multiple failure attempts associated with one submitted job.
{
"job": {
"config": {
"fetch_data": {
"url": "https://example.com/average-files/punctuation1.mp3"
},
"notification_config": [
{
"contents": [
"jobinfo"
],
"url": "https://example.com"
}
],
"transcription_config": {
"language": "de"
},
"type": "transcription"
},
"created_at": "2021-07-19T09:02:17.283Z",
"data_name": "",
"duration": 4,
"errors": [
{
"message": "Error in sending notification: unable to send notification: HTTPError: Post \"https://example.com/500?id=1uyo82b1bv&status=success\": context deadline exceeded (Client.Timeout exceeded while awaiting headers), retrying",
"timestamp": "2021-07-19T09:04:11.080Z"
},
{
"message": "Error in sending notification: unable to send notification: Respone status: 500, retrying",
"timestamp": "2021-07-19T09:04:26.619Z"
},
{
"message": "Error in sending notification: unable to send notification: Respone status: 500, retrying",
"timestamp": "2021-07-19T09:04:47.090Z"
},
{
"message": "unable to send notification: unable to send notification: Respone status: 500",
"timestamp": "2021-07-19T09:05:17.347Z"
},
{
"message": "Sending notification failed",
"timestamp": "2021-07-19T09:05:17.570Z"
}
],
"id": "1uyo82b1bv",
"status": "done"
}
}
Metadata and job tracking
It is now possible to attach richer metadata to a job using the tracking configuration. The tracking object contains the following properties:
| Name | Type | Description | Notes |
|---|---|---|---|
| title | str | The title of the job. | [optional] |
| reference | str | External system reference. | [optional] |
| tags | list[str] | [optional] | |
| details | object | Customer-defined JSON structure. | [optional] |
This allows you to track the job through your own management workflow using whatever information is relevant to you.
Metadata and job tracking configuration example
{
"type": "transcription",
"transcription_config": {
"language": "en"
},
"tracking": {
"title": "ACME Q12018 Statement",
"reference": "/data/clients/ACME/statements/segs/2018Q1-seg8",
"tags": [
"quick-review",
"segment"
],
"details": {
"client": "ACME Corp",
"segment": 8,
"seg_start": 963.201,
"seg_end": 1091.481
}
}
}
Word Tagging
Profanity Tagging
Speechmatics now outputs in JSON transcript only a metadata tag to indicate whether a word is a profanity or not. This is for the following languages:
- English (EN)
- Italian (IT)
- Spanish (ES)
For each language pack, the list of profanities is not alterable. Users do not have to take any action to access this - it is provided in our JSON output as standard. Customers can use this tag for their own post-processing in order to identify, redact, or obfuscate profanities and integrate this data into their own workflows. An example of how this looks is below.
"results": [
{
"alternatives": [
{
"confidence": 1.0,
"content": "$PROFANITY",
"language": "en",
"speaker": "UU",
"tags": [
"profanity"
]
}
],
"end_time": 18.03,
"start_time": 17.61,
"type": "word"
}
]
Disfluency Tagging
Speechmatics now outputs in JSON transcript only a metadata tag to indicate whether a word is a disfluency or not in the English language only. A disfluency here refers to a set list of words in English that imply hesitation or indecision. Please note while disfluency can cover a range of items like stuttering and interjections, here it is only used to tag words such as 'hmm' or 'umm'. Users do not have to take any action to access this - it is provided in our JSON output as standard. Customers can use this tag for their own post-processing workflows. An example of how this looks is below:
"results": [
{
"alternatives": [
{
"confidence": 1.0,
"content": "hmm",
"language": "en",
"speaker": "UU",
"tags": [
"disfluency"
]
}
],
"end_time": 18.03,
"start_time": 17.61,
"type": "word"
}
]
Domain Language Packs
Some Speechmatics language packs are optimized for specific domains where high accuracy for specific vocabulary and terminology is required. Using the domain parameter provides additional transcription accuracy, and must be used in conjunction with a standard language pack (this is currently limited to the "finance" domain and supports the "en" language pack). An example of how this looks is below:
{
"type": "transcription",
"transcription_config": {
"language": "en",
"domain": "finance"
}
}
These domain language packs are built on top of our global language packs so give the highest accuracy in different acoustic environments that our customers have come to expect.
It is expected that whilst there will be improvements for the specific domain there can be degradation in accuracy for other outside domains.