How to use the Speechmatics Batch SaaS
Basics
This section will show how to submit an audio file for batch transcription, check the status of a job, and to retrieve a transcript in a supported format once the job is done. It then shows how to configure a transcription request to take advantage of other Speechmatics features.
This section will show you
- How to submit a file to the Speechmatics Batch SaaS
- How to poll on any job's status
- How to retrieve a transcript in a supported format
- How to delete a job and all associated data
In all requests your Authorization Token must always be passed in the header of any request
For these examples there are linked videos, and examples provided for Windows and for Linux (Ubuntu).
Important Note on Examples
All examples below show, where relevant, an example job configuration, and how to submit, retrieve and delete job requests and their output via Linux or Windows
Job configuration itself in these examples is enclosed within a file called config.json when submitted to the Speechmatics Batch SaaS. These examples should work in Windows CME mode and Powershell.
Submitting a job
Speechmatics Batch SaaS Demo: Post Job Request
The simplest configuration for a transcription job is simply to specify:
- The
typeof request you want. This is alwaystranscription - The
languagethat you wish to use. This is a two digit language code following ISO639-1 format or a three digit language code following ISO639-3 format. It must be one of the language codes supported by Speechmatics for transcription:
Below is an example of a basic configuration
config='{
"type": "transcription",
"transcription_config": { "language": "en" }
}'
In examples below, job configuration is enclosed within a file called config.json. This file can be extended or modified as you wish when using Speechmatics features
Requesting an enhanced model
Speechmatics supports two different models within each language pack; a standard or an enhanced model. The standard model is the faster of the two, whilst the enhanced model provides a higher accuracy, but a slower turnaround time.
The enhanced model is a premium model. Please contact your account manager or Speechmatics if you would like access to this feature.
Free trial users can access both enhanced and standard models without first speaking to a member of the Speechmatics team.
An example of requesting the enhanced model is below
{
"type": "transcription",
"transcription_config": {
"language": "en",
"operating_point": "enhanced"
}
}
Please note: standard, as well as being the default option, can also be explicitly requested with the operating_point parameter.
Linux example
curl -L -X POST https://asr.api.speechmatics.com/v2/jobs/ -H "Authorization: Bearer NDFjOTE3NGEtOWVm" -F data_file=@example.wav -F config="$(cat config.json)" | jq
Windows example
curl.exe -L -X POST https://asr.api.speechmatics.com/v2/jobs/ -H "Authorization: Bearer NDFjOTE3NGEtOWVm" -F data_file=@example.wav -F config="<config.json" | jq
Here NDFjOTE3NGEtOWVm is a sample authorization token. You would replace this with the token that you have been provided with.
A successful request will return a HTTP 201 response, and will contain a unique alphanumeric Job ID, which will be returned as id in the HTTP response. For full details see the Jobs API Reference.
An example response will look like this:
HTTP/1.1 201 Created
Content-Length: 20
Content-Type: application/json
Request-Id: 4d46aa73e1a4c5a6d4ba6c31369e7b2e
Strict-Transport-Security: max-age=15724800; includeSubDomains
X-Azure-Ref: 0XdIUXQAAAADlflaR0qvRQpReZYf+q+FHTE9OMjFFREdFMDMwNwBhN2JjOWQ4MC02YjBiLTQ1NWEtYjE3MS01NGJkZmNiYWE0YTk=
Date: Thu, 27 Jun 2019 14:27:45 GMT
{"id":"dlhsd8d69i"}
In addition to the Job ID The Request-ID uniquely identifies your API request. If you ever need to raise a support ticket we recommend that you include the Request-ID if possible, as it will help to identify your job. The Strict-Transport-Security response header indicates that only HTTPS access is allowed. The X-Azure-Ref response header identifies the load-balancer request.
If you do not specify an auth token in the request, or if the token provided is invalid, then you'll see a 401 status code like this:
HTTP/1.1 401 Authorization Required
Checking Job Status
A 201 Created status indicates that the job was accepted for processing.
If you wish to retrieve a particular job, you can do so using the job id for up to 7 days, after which time it will be automatically deleted in accordance with our data retention policy.
You can make a GET request to check the status of that job as follows:
Unix/Ubuntu
curl -L -X GET https://asr.api.speechmatics.com/v2/jobs/dlhsd8d69i -H "Authorization: Bearer NDFjOTE3NGEtOWVm" | jq
Windows
curl.exe -L -X GET https://asr.api.speechmatics.com/v2/jobs/dlhsd8d69i -H "Authorization: Bearer NDFjOTE3NGEtOWVm" | jq
The response
The response is a JSON object containing details of the job, with the status field showing whether the job is still processing or not. A value of done means that the transcript is now ready. Jobs will typically take less than half the audio length to process; so an audio file that is 40 minutes in length should be ready within 20 minutes of submission. See Jobs API Reference for details. An example response looks like this:
HTTP/1.1 200 OK
Content-Type: application/json
{
"job": {
"config": {
"notification_config": null,
"transcription_config": {
"additional_vocab": null,
"channel_diarization_labels": null,
"language": "en"
},
"type": "transcription"
},
"created_at": "2019-01-17T17:50:54.113Z",
"data_name": "example.wav",
"duration": 275,
"id": "yjbmf9kqub",
"status": "running"
}
}
Possible job status types include:
- running
- done
- rejected
Poll for more than one job
If you have submitted multiple jobs, you can retrieve a list of the 100 most recent jobs submitted in the past 7 days by making a GET request without a Job ID. If a job has been deleted it will not be included in the list.
Unix/Ubuntu
curl -L -X GET https://asr.api.speechmatics.com/v2/jobs/ -H "Authorization: Bearer NDFjOTE3NGEtOWVm" | jq
Windows
curl.exe -L -X GET https://asr.api.speechmatics.com/v2/jobs/ -H "Authorization: Bearer NDFjOTE3NGEtOWVm" | jq
The response
Here is an example result:
{
"jobs": [
{
"config": {
"transcription_config": {
"language": "en"
},
"type": "transcription"
},
"created_at": "2021-02-03T17:16:05.500Z",
"data_name": "audio.mp3",
"duration": 143,
"id": "bhyy42zcbb",
"status": "done"
},
{
"config": {
"transcription_config": {
"language": "en"
},
"type": "transcription"
},
"created_at": "2021-02-03T17:16:04.583Z",
"data_name": "audio.mp3",
"duration": 146,
"id": "zg4m8z4jtn",
"status": "done"
}
]
}
Retrieving a transcript
Speechmatics Batch SaaS Demo: Retrieving Transcripts
Transcripts can be retrieved as follows:
Unix/Ubuntu
curl -L -X GET https://asr.api.speechmatics.com/v2/jobs/yjbmf9kqub/transcript -H "Authorization: Bearer NDFjOTE3NGEtOWVm" | jq
Windows
curl.exe -L -X GET https://asr.api.speechmatics.com/v2/jobs/yjbmf9kqub/transcript -H "Authorization: Bearer NDFjOTE3NGEtOWVm" | jq
The supported default transcription output is json-v2. Other formats supported are srt (SubRip subtitle format) and txt (plain text). The format is set using the format query string parameter. Below are examples for retrieving a transcript in TXT format:
Unix/Ubuntu
curl -L -X GET "https://asr.api.speechmatics.com/v2/jobs/yjbmf9kqub/transcript?format=txt" -H "Authorization: Bearer NDFjOTE3NGEtOWVm" | jq
Windows
curl.exe -L -X GET https://asr.api.speechmatics.com/v2/jobs/yjbmf9kqub/transcript?format=txt -H "Authorization: Bearer NDFjOTE3NGEtOWVm" | jq
See Jobs API Reference for details. If you require multiple transcripts simultaneously, this is supported via the notifications functionality in the configuration object and is shown here
Deleting a completed job
Jobs will be automatically deleted after 7 days in accordance with our data retention policy. You can remove a completed job before it is automatically deleted as follows:
Unix/Ubuntu
curl -L -X DELETE https://asr.api.speechmatics.com/v2/jobs/yjbmf9kqub -H "Authorization: Bearer NDFjOTE3NGEtOWVm" | jq
Windows
curl.exe -L -X DELETE https://asr.api.speechmatics.com/v2/jobs/yjbmf9kqub -H "Authorization: Bearer NDFjOTE3NGEtOWVm" | jq
The Response
If the DELETE request is successful, you will receive a response, showing the jobID and a status of deleted
{
"job": {
"config": {
"transcription_config": {
"language": "en"
},
"type": "transcription"
},
"created_at": "2021-02-19T09:47:09.561Z",
"data_name": "bbcnews.mp3",
"duration": 377,
"id": "ovrdc3el3w",
"status": "deleted"
}
}
Deleting a running job
A DELETE request with no query parameters will only remove completed jobs. To remove a job that may still be running, you can use DELETE with the force=true parameter as follows:
Unix/Ubuntu
curl -L -X DELETE https://asr.api.speechmatics.com/v2/jobs/yjbmf9kqub?force=true -H "Authorization: Bearer NDFjOTE3NGEtOWVm" | jq
Windows
curl.exe -L -X DELETE https://asr.api.speechmatics.com/v2/jobs/yjbmf9kqub?force=true -H "Authorization: Bearer NDFjOTE3NGEtOWVm" | jq
The Response
If the DELETE request is successful, you will receive a response, showing the jobID and a status of deleted
{
"job": {
"config": {
"transcription_config": {
"language": "en"
},
"type": "transcription"
},
"created_at": "2021-02-19T09:47:09.561Z",
"data_name": "bbcnews.mp3",
"duration": 377,
"id": "ovrdc3el3w",
"status": "deleted"
}
}
The transcript
When retrieving the transcript, and requesting json-v2 format, the following information is returned
-
The format. The API format. This will be 2.8
-
The
jobproperty. This contains information like:created at: The timestamp for when the job was created, in UTCdata_name: The file name of the submitted mediaduration: The length of the file in secondsid: The unique Job ID associated wih the file
-
The
metadataproperty. This includes:created_at: when the transcription output was created. Note: this will be a later time to thecreated_atresult injob, which takes into account time taken to process the job and other system interactionslanguage_pack_info: Properties of the language packlanguage_description: Full descriptive name of the language, e.g. 'Japanese'word_delimiter: The character to use to separate wordswriting_direction: The direction the words in the language are written and read initn: Whether or not ITN (inverse text normalization) is available for the language pack. Refer to documentation here for more information about ITNadapted: Whether or not language model adaptation has been applied to the language pack
transcription_config: The configuration requested when the job was submitted
-
The
resultssection. This will contain:type: One of 'word', 'entity', 'punctuation' or 'speaker_change'attaches_to: Iftypeis 'punctuation', details the attachment direction of the punctuation mark. This information can be used to produce a well-formed text representation by placing theword_delimiterfromlanguage_pack_infoon the correct side of the punctuation markprevious: Attaches the puctuation to the previous word, e.g 'a. b'next: Attaches the puctuation to the next word, e.g 'a .b'both: Attaches the puctuation to both previous and next words, e.g 'a.b'none: Attaches the puctuation to neither previous nor next words, e.g 'a . b'
start_time: The start of the word or punctuation, marked in secondsend_time: The end of the word or punctuation, marked in secondsis_eos: Whether a punctuation mark is the end of the sentence or not. The value here is boolean (e.g. true or false). This value will not always be shownalternatives: For 'word' and 'punctuation' results this contains a list of possible alternative options for the word/symbolcontent: A word or punctuation mark. Whenenable_entitiesis requested this can be multiple words with spaces, for example "17th of January 2022".confidence: This is a score between 0 and 1.speaker: If speaker diarization is enabled, which speaker is talking. Speakers are numberedS1,S2S3etc. If diarization is not chosen or fails to detect a speaker the results will beUUlanguage: the language spoken. This will always be in the language that you have requestedtags: any metadata tag about the type of word spoken. This will beprofanityfor a set list of words in English onlychannel: Only shown if channel diarization is enabled. The default value ischannel_#, where#is an integer that corresponds to the channel number in the audio file. Up to 6 channels in one file are supported. If channel diarization labels are requested in the job request (e.g.caller,agent) these would be shown in thechannelvalue instead and override the default
entity_class: Only ifenable_entitiesis requested and an entity is detected, entity_class will represent the type of entity the word(s) have been formatted asspoken_form: Only ifenable_entitiesis requested and an entity is detected, this is a list of words without formatting applied. This follows the results list API formatting.written_form: Only ifenable_entitiesis requested and an entity is detected, this is a list of formatted words that matches the entity content but with individual estimated timing and confidences. This follows the results list API formatting.
An example transcript using the JSON output format is shown:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/vnd.speechmatics.v2+json
Request-Id: aad4eb68bca69f3f277d202456bb0b15
Strict-Transport-Security: max-age=15724800; includeSubDomains
X-Azure-Ref: 0ztQUXQAAAAA4ifGtw2COQKyb52QoNgX4TE9OMjFFREdFMDMyMABhN2JjOWQ4MC02YjBiLTQ1NWEtYjE3MS01NGJkZmNiYWE0YTk=
Date: Thu, 27 Jun 2019 14:38:05 GMT
{
"format":"2.8",
"job":{
"created_at":"2019-01-17T17:50:54.113Z",
"data_name":"example.wav",
"duration":275,
"id":"yjbmf9kqub"
},
"metadata":{
"created_at":"2019-01-17T17:52:26.222Z",
"language_pack_info": {
"adapted": false,
"itn": true,
"language_description": "English",
"word_delimiter": " ",
"writing_direction": "left-to-right"
},
"transcription_config":{
"diarization":"none",
"language":"en"
},
"type":"transcription"
},
"results":[
{
"alternatives":[
{
"confidence":0.9,
"content":"Just",
"language":"en",
"speaker":"UU"
}
],
"end_time":1.07,
"start_time":0.9,
"type":"word"
},
{
"alternatives":[
{
"confidence":1,
"content":"this",
"language":"en",
"speaker":"UU"
}
],
"end_time":1.44,
"start_time":1.11,
"type":"word"
},
{
"alternatives":[
{
"confidence":1,
"content":".",
"language":"en",
"speaker":"UU"
}
],
"attaches_to":"previous",
"end_time":273.64,
"start_time":273.64,
"type":"punctuation"
}
]
}
You should be aware that for most non-English languages, you will be working with characters outside the ASCII range. Ensure that the programming language or client framework you are using is able to output the human-readable or machine-readable format that you require for your use case. Some client bindings will assume that non-ASCII characters are escaped, others do not. In most cases there will be a parameter that enables you to decide which you want to output.
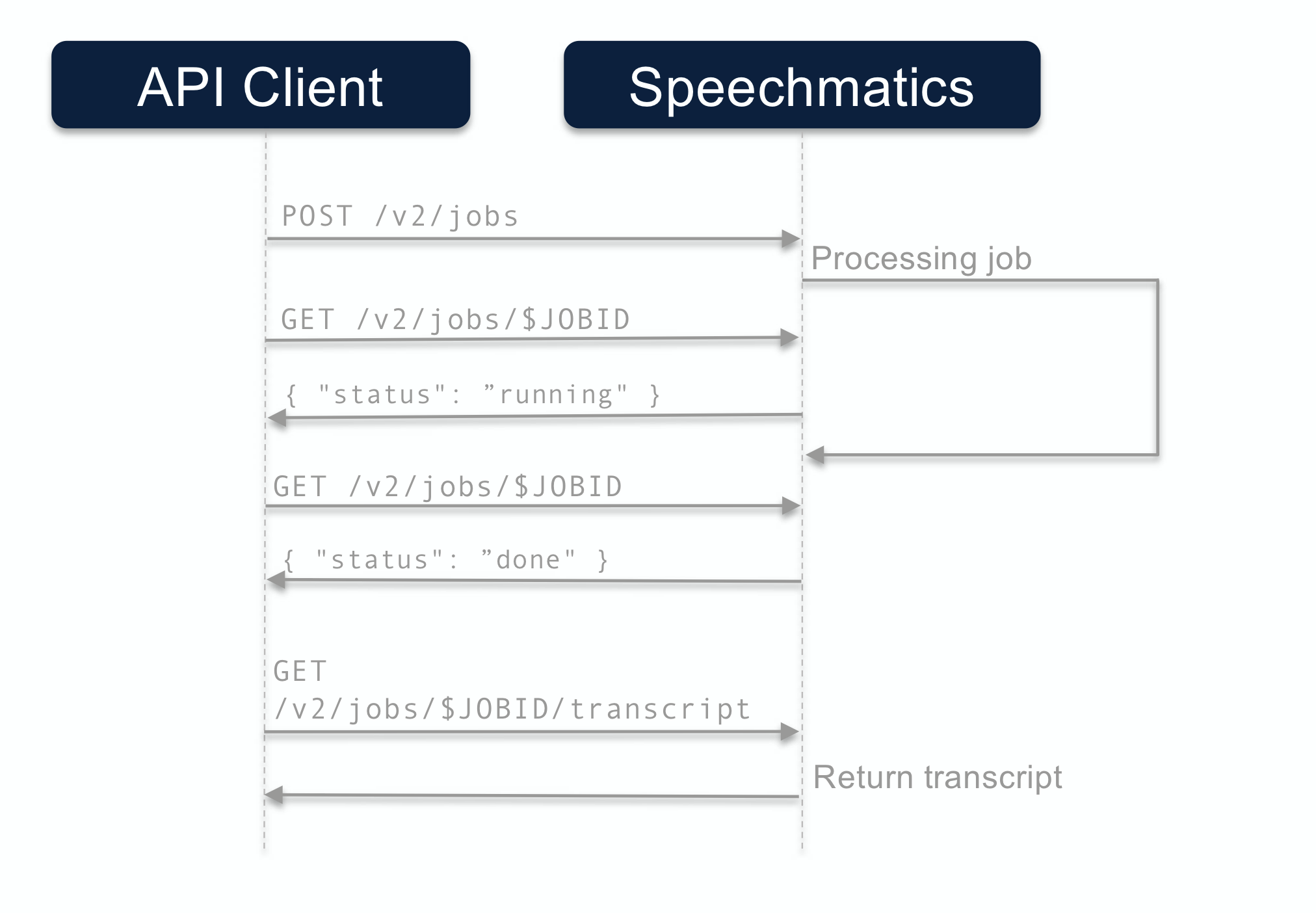
Polling call flow
The call flow for the polling method looks like this: