Custom Dictionary Cache
The custom dictionary cache is only available in the Real-time Virtual Appliance.
The Speechmatics Real-time Virtual Appliance includes a cache mechanism for custom dictionaries. By using this cache mechanism, the appliance is able to reduce the time needed for processing a custom dictionary before starting the recognition of an audio stream.
Once the Real-time Virtual Appliance has started a recognition session with a given custom dictionary, any subsequent streams with the identical custom dictionary sent to the appliance by any client will benefit from a reduced setup time. Transcription requests using an already cached custom dictionary will start recognition in less than 3 seconds if the custom dictionary is up to our recommended limit of 1000 words.
When using V1 API the setup time spent processing a cached entry is about 3 seconds longer compared to V2 API.
Size available
The size available for storing Custom Dictionary Cache entries depends on the variant of the Real-time Virtual Appliance.
| Variant | Cache Space |
|---|---|
| nano | 100MB |
| mini | 150MB |
| midi | 200MB |
| maxi | 250MB |
| plus | 300MB |
Size of cache entries
The entry size varies depending on the amount of information included in the custom dictionary. For guidance, the table below displays some values for different custom dictionaries.
| Custom Dictionary | Cache Used Bytes | Cache Entry Size |
|---|---|---|
| None (empty cache) | 14KiB | NA |
| 1000 words | 120KiB | 106KiB |
| 1000 words + 1 sounds like each | 188KiB | 174KiB |
The custom dictionary cache needs to keep certain metadata files in order to function. For this reason the used_bytes reported will never be 0, even if the cache is not storing any entry. The amount of storage used by an empty cache is typically around 14KiB.
Cache life cycle
When a custom dictionary is used for a transcription, it is automatically cached by the Real-time Virtual Appliance. This allows for a reduced setup time on any further transcriptions using the same custom dictionary. Custom dictionary cache is persisted in disk, making it available between reboots. If there is no space left in the cache for a new entry, entries are deleted in order of when they were last used when submitting a job.
Cache entries are ready to be consumed by any subsequent transcription request, from any client, after a RecognitionStarted message is emitted by the Real-time Appliance. For this reason, transcription requests made in parallel, each with the same custom dictionary that is new to the appliance, won’t benefit from a reduced setup time.
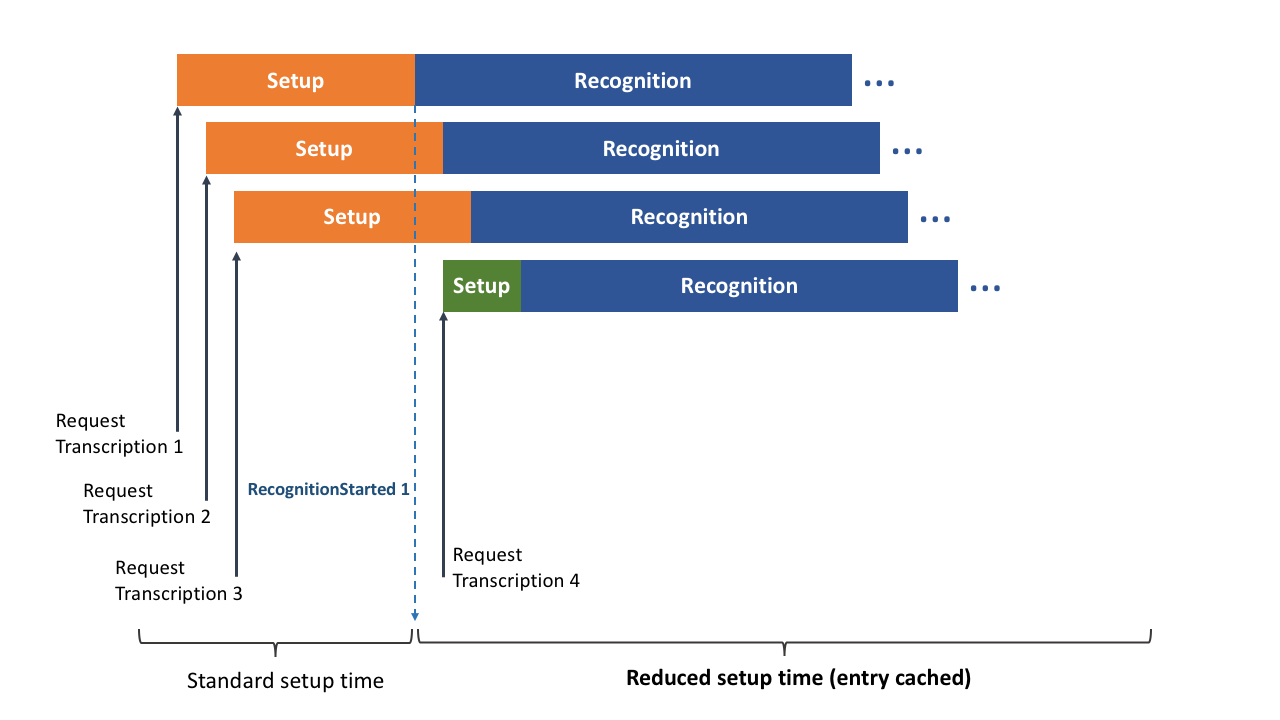
A custom dictionary could be cached beforehand by requesting a transcription for an empty audio file. After receiving the RecognitionStarted message from the appliance, other requests using the same custom dictionary will benefit from a reduced startup time.
Administering the Cache
When the Real-time Virtual Appliance is started for the first time the cache will be empty. The management API allows you to retrieve cache usage data and to purge the cache contents.
View Cache Usage
Cache usage reports the maximum cache size and the used number of bytes in the cache.
In order to retrieve usage statistics, send a GET request to the /v1/management/cache endpoint:
curl -L -X GET http://${APPLIANCE_HOST}:8080/v1/management/cache \
-H 'Accept: application/json' \
| jq
Here is an example response:
{
"total_bytes": "105188352",
"used_bytes": "192512"
}
Purge Cache Contents
It is possible to remove all contents in the cache.
In order to purge the cache contents, send a DELETE request to the /v1/management/cache endpoint:
curl -L -X DELETE http://${APPLIANCE_HOST}:8080/v1/management/cache \
-H 'Accept: application/json' \
| jq
Here is an example response:
{
"confirmation": "Custom dictionary cache purged successfully",
"usage": {
"total_bytes": "105188352",
"used_bytes": "14336"
}
}