Introduction
Overview
The WebSocket Speech API allows communication from a client application over a WebSocket connection to the Speechmatics ASR engine (as implemented in the Real-Time Virtual Appliance or the standalone Real-Time Container). This connection provides the ability to convert a stream of audio into a transcript providing the words and timing information as the live audio is processed.
The WebSocket API can be used directly as described in this document; client libraries and frameworks that support WebSockets are available for most popular programming languages. Speechmatics provides reference Python libraries that can be used to wrap the WebSocket interface, and provide the ability to connect directly to a microphone or RTSP feed.
This document will guide you through setting up and configuring the WebSocket connection, and explain which features are available via the API.
Terms
For the purposes of this guide the following terms are used.
| Term | Description |
|---|---|
| Client | An application connecting to the Real-time Virtual Appliance using the Speech API. The client will provide audio containing speech, and process the transcripts received as a result. |
| Server | The Real-Time Container or Applaince providing the ASR engine which processes human speech and returns transcripts in real-time. |
| Management API | The REST API that allows administrators to manage the virtual appliance over port 8080. To access the documentation you can use the following URI: http://${APPLIANCE_HOST}:8080/help/, where ${APPLIANCE_HOST} is the IP address or hostname of your appliance. |
| Speech API | The WebSocket API that allows users to submit ASR jobs over server port 9000. The endpoint wss://${APPLIANCE_HOST}:9000/v2 is used for the Speech API. This is the API that is described in this document. |
| Real-Time Container | A Docker container that provides real-time ASR transcription. |
| Real-Time Virtual Appliance | An appliance (VM) that provides real-time ASR transcription. |
Construction
Input Formats
A wide variety of input sources are supported, including:
- Raw audio (microphone)
- File (.wav, .mp3 and .mp4 are tested)
- RTMP, RTSP or HLS stream
A Python client library is supplied that shows how to get data from some of these sources.
If you attempt to use an audio file format that is not supported, then you will see the following error message:
Error / job_error: An internal error happened while processing your file. Please check that your audio format is supported.
Transcription Output Format
The transcript output format from the Speech API is JSON. It is described in detail in the API Reference. There are two types of transcript that are provided: final transcripts and partial transcripts. Which one you decide to consume will depend on your use case, and your latency and accuracy requirements.
Final transcripts
Final transcripts are sentences or phrases that are provided based on the Speechmatics ASR engine automatically determining the best point at which to provide the transcript to the client. These transcripts occur at irregular intervals. Once output, these transcripts are considered final, they will not be updated after output.
The timing of the output is determined by Speechmatics based on the ASR algorithm. This is affected by pauses in speech and other parameters resulting in a latency between audio input and output of up to 10 seconds. This 10 second default can be changed with the max_delay property in transcription_config when starting the recognition session.
Final transcripts provide the most accurate transcription.
Partial transcripts
A partial transcript is a transcript that can be updated at a later point in time. It is believed to be correct at the time of output, but once further audio data is available, the Speechmatics ASR engine may use the additional context that is available to update parts of the transcript that have already been output.
These transcripts are output as soon as any transcript is available, regardless of accuracy, and are therefore available at very low latency. These are the fastest way to consume transcripts but at the cost of needing to accept updates at a later point. Partial transcripts provide latency values between audio input and initial output of less than 1 second.
This is the least accurate transcription method, but can be used in conjunction with the final transcripts to enable fast display of the transcript, adjusting over time.
Partial transcripts must be explicitly enabled (using the enable_partials setting) in the config for the session, otherwise only final transcripts will be output.
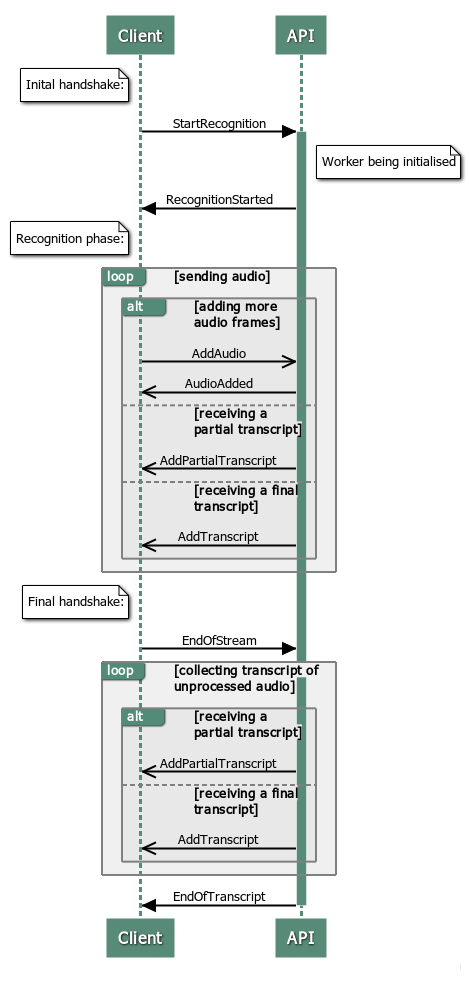
The WebSocket Protocol
WebSockets are used to provide a two-way transport layer between your client and the Real-Time Appliance or Container, enabling use with most modern web-browsers, and programming languages. See RFC 6455 for the detailed specification of the WebSocket protocol.
The wire protocol used with the WebSocket consists mostly of packets of stringified JSON objects which comprise a message name, plus other fields that are message dependant. The only exception is that a binary message is used for transmitting the audio.
You can develop your real time client using any programming language that supports WebSockets. This document provides a list of the messages that are required for the client and server communication. Some of the messages are required to be sent in a particular order (outlined below) whilst others are optional. There are some examples provided at the end of this document on how to access the Speech API using JavaScript.
When implementing your own websocket client, we recommend using a ping/pong timeout of 60 seconds. More details about ping/pong messages can be found in the WebSocket RFC here: https://tools.ietf.org/html/rfc6455#page-37.
For a working Python example, please refer to our reference Python client implementations.
If you are using the Real-Time Virtual Appliance you can use the smwebsocket-py library, which is available for download. Please contact support@speechmatics.com for details of how to download this Python client.
If you are using the standalone Real-Time Container you can use the speechmatics-python library. Please contact support@speechmatics.com for details of how to download this Python client.