Real-time Container API Guide
This page specifies the Real-time API at its current state. The basic elements in the communication are the following:
- Client - An application connecting to the API, providing the audio and processing the transcripts received from the Server.
- Server (also called API) - An entry point of the API, allows external connections and provides the transcripts back.
- Worker - An internal speech recognizer. This is an internal entity that actually runs the heavy speech recognition.
This is a specification for Speechmatics Real-time API version 2.7
Client ↔ API endpoint
The communication is done using WebSockets, which are implemented in most of the modern web-browsers, as well as in many common programming languages (namely C++ and Python, for instance using http://autobahn.ws/).
Messages
Each message that the Server accepts is a stringified JSON object with the following fields:
message(String): The name of the message we are sending. Any other fields depend on the value of themessageand are described below.
The messages sent by the Server to a Client are stringified JSON objects as well.
The only exception is a binary message sent from the Client to the Server containing a chunk of audio which will be referred to as AddAudio.
The following values of the message field are supported:
StartRecognition
Initiates recognition, based on details provided in the following fields:
message: "StartRecognition"audio_format(Object:AudioType): Required. Audio stream type you are going to send: see Supported audio types.transcription_config(Object:TranscriptionConfig): Required. Set up configuration values for this recognition session, see Transcription config.
A StartRecognition message must be sent exactly once after the WebSocket connection is opened. The client must wait for a RecognitionStarted message before sending any audio.
In case of success, a message with the following format is sent as a response:
message: "RecognitionStarted"id(String): Required. A randomly-generated GUID which acts as an identifier for the session. e.g. "807670e9-14af-4fa2-9e8f-5d525c22156e".
In case of failure, an error message is sent, with type being one of the following:
invalid_model, invalid_audio_type, not_authorised, insufficient_funds, not_allowed, job_error.
An example of the StartRecognition message:
{
"message": "StartRecognition",
"audio_format": {
"type": "raw",
"encoding": "pcm_f32le",
"sample_rate": 16000
},
"transcription_config": {
"language": "en",
"output_locale": "en-US",
"diarization": "speaker_change",
"max_delay": 3.5,
"max_delay_mode": "flexible",
"enable_partials": true,
}
}
Explaining Max Delay Mode
Users can specify the latency of the Real-time Speechmatics engine using the max_delay parameter. If a value of '5' was chosen, this would mean that transcripts would always be returned in 5 seconds from the word first being spoken. This happens even if a word is detected that may overrun that threshold. In some cases this can lead to inaccuracies in recognition and in finalised transcripts. This can be especially noticeable with key entities such as numerals, currencies, and dates.
max_delay_mode allows a greater flexibility in this latency only when a potential entity has been detected. Entities are common concepts such as numbers, currencies and dates, and can be seen in more detail here.
There are two potential options for max_delay_mode: fixed and flexible. If no option is chosen, the default is flexible. Where an entity is detected with flexible, the latency of a transcript may exceed the threshold specified in max_delay, however the recognition of entities will be more accurate. If a user specifies fixed, the transcript will be returned in segments that will never exceed the max_delay threshold, even if this causes inaccuracies in entity recognition.
SetRecognitionConfig
Allows the Client to configure the recognition session even after the initial StartRecognition message without restarting the connection. This is only supported for certain parameters.
message: "SetRecognitionConfig"transcription_config(Object:TranscriptionConfig): A TranscriptionConfig object containing the new configuration for the session, see Transcription config.
The following is an example of such a configuration message:
{
"message": "SetRecognitionConfig",
"transcription_config": {
"language": "en",
"max_delay": 3.5,
"enable_partials": true
}
}
Note: The language property is a mandatory element in the transcription_config object; however it is not possible to change the language mid-way through the session (it will be ignored if you do). It is only possible to modify the following settings through a SetRecognitionConfig message after the initial StartRecognition message:
max_delaymax_delay_modeenable_partials
If you wish to alter any other parameters you must terminate the session and restart with the altered configuration. Attempting otherwise will result in an error.
The example above starts a session with the Global English model ready to consume raw PCM encoded audio with float samples at 16kHz. It also includes an additional_vocab list containing the names of different types of pasta. speaker_change diarization is enabled, and partials are enabled meaning that AddPartialTranscript messages will be received as well as AddTranscript messages. Punctuation is configured to restrict the set of punctuation marks that will be added to only commas and full stops.
AddAudio
Adds more audio data to the recognition job started on the WebSocket using StartRecognition. The server will only accept audio after it is initialized with a job, which is indicated by a RecognitionStarted message. Only one audio stream in one format is currently supported per WebSocket (and hence one recognition job). AddAudio is a binary message containing a chunk of audio data and no additional metadata.
AudioAdded
If the AddAudio message is successfully received, an AudioAdded message is sent as a response. This message confirms that the Server has accepted the data and will make a corresponding Worker process it. If the Client implementation holds the data in an internal buffer to resubmit in case of an error, it can safely discard the corresponding data after this message. The following fields are present in the response:
message: "AudioAdded"seq_no(Int): Required. An incrementing number which is equal to the number of audio chunks that the server has processed so far in the session. The count begins at 1 meaning that the 5thAddAudiomessage sent by the client, for example, should be answered by anAudioAddedmessage withseq_noequal to 5.
Possible errors:
data_error,job_error,buffer_error
When sending audio faster than real time (for instance when sending files), make sure you don't send too much audio ahead of time. For large files, this causes the audio to fill out networking buffers, which might lead to disconnects due to WebSocket ping/pong timeout. Use AudioAdded messages to keep track what messages are processed by the engine, and don't send more than 10s of audio data or 500 individual AddAudio messages ahead of time (whichever is lower).
Implementation details
Under special circumstances, such as when the client is sending the audio data faster than real time, the Server might read the data slower than the Client is sending it. The Server will not read the binary AddAudio message if it is larger than the internal audio buffer on the Server. Note that for each Worker, there is a separate buffer. In that case, the server will read any messages coming in on the WebSocket, until enough space is made in the buffer by passing the data to a corresponding Worker. The Client will only receive the corresponding AudioAdded response message once the binary data is read. The WebSocket might eventually fill all the TCP buffers on the way, causing a corresponding WebSocket to fail to write and close the connection with prejudice. The Client can use the bufferedAmount attribute of the WebSocket to prevent this.
AddTranscript
This message is sent from the Server to the Client, when the Worker has provided the Server with a segment of transcription output. It contains the transcript of a part of the audio the Client has sent using AddAudio - the final transcript. These messages are also referred to as finals. Each message corresponds to the audio since the last AddTranscript message. The transcript is final - any further AddTranscript or AddPartialTranscript messages will only correspond to the newly processed audio.
An AddTranscript message is sent when we reach an endpoint (end of a sentence or a phrase in the audio), or after 10s if we haven't reached such an event. This timeout can be further configured by setting transcription_config.max_delay in the StartRecognition message.
message: "AddTranscript"metadata(Object): Required.start_time(Number): Required. An approximate time of occurrence (in seconds) of the audio corresponding to the beginning of the first word in the segment.end_time(Number): Required. An approximate time of occurrence (in seconds) of the audio corresponding to the ending of the final word in the segment.transcript(String): Required. The entire transcript contained in the segment in text format. Providing the entire transcript here is designed for ease of consumption; we have taken care of all the necessary formatting required to concatenate the transcription results into a block of text. This transcript lacks the detailed information however which is contained in theresultsfield of the message - such as the timings and confidences for each word.
results(List:Object):type(String): Required. One of 'word', 'entity', 'punctuation' or 'speaker_change'. 'word' results represent a single word. 'punctuation' results represent a single punctuation symbol. 'word' and 'punctuation' results will both have one or morealternativesrepresenting the possible alternatives we think the word or punctuation symbol could be. 'entity' is only a possible type ifenable_entitiesis set totrueand indicates a formatted entity. 'speaker_change' results however will have an emptyalternativesfield. 'speaker_change' results will only occur when using speaker_change diarization.start_time(Number): Required. The start time of the result relative to the start_time of the whole segment as described inmetadata.end_time(Number): Required. The end time of the result relative to the start_time of the segment in the message as described inmetadata. Note that punctuation symbols and speaker_change results are considered to be zero-duration and thus for those resultsstart_timeis equal toend_time.is_eos(Boolean): Optional. Only present for 'punctuation' results. This indicates whether or not the punctuation mark is considered an end-of-sentence symbol. For example full-stops are an end-of-sentence symbol in English, whereas commas are not. Other languages, such as Japanese, may use different end-of-sentence symbols.alternatives(List:Object): Optional. For 'word' and 'punctuation' results this contains a list of possible alternative options for the word/symbol.content(String): Required. A word or punctuation mark. Whenenable_entitiesis requested this can be multiple words with spaces, for example "17th of January 2022".confidence(Number): Required. A confidence score assigned to the alternative. Ranges from 0.0 (least confident) to 1.0 (most confident).display(Object): Optional. Information about how the word/symbol should be displayed.direction(String): Required. Either 'ltr' for words that should be displayed left-to-right, or 'rtl' vice versa.
language(String): Optional. The language that the alternative word is assumed to be spoken in. Currently this will always be equal to the language that was requested in the initialStartRecognitionmessage.tags(array): Optional. Only[disfluency]and[profanity]are displayed. This is a set list of profanities and disfluencies respecitvely that cannot be altered by the end user.[disfluency]is only present in English, and[profanity]is present in English, Spanish, and Italian.
entity_class(String): Optional. Ifenable_entitiesis requested in the startTranscriptionConfig request, and an entity is detected,entity_classwill represent the type of entity the word(s) have been formatted as.spoken_form(List:Object): Optional. Ifenable_entitiesis requested in the startTranscriptionConfig request, and an entity is detected, this is a list of words without formatting applied. This follows theresultslist API formatting.written_form(List:Object): Optional. Ifenable_entitiesis requested in the startTranscriptionConfig request, and an entity is detected, this is a list of formatted words that matches the entitycontentbut with individual estimated timing and confidences. This follows theresultslist API formatting.
AddPartialTranscript
A partial-transcript message. The structure is the same as AddTranscript. A partial transcript is a transcript that can be changed and expanded by a future AddTranscript or AddPartialTranscript message and corresponds to the part of audio since the last AddTranscript message. For AddPartialTranscript messages the confidence field for alternatives has no meaning and will always be equal to 0.
Partials will only be sent if transcription_config.enable_partials is set to true in the StartRecognition message.
EndOfStream
This message is sent from the Client to the API to announce that it has finished sending all the audio that it intended to send. No more AddAudio message are accepted after this message. The Server will finish processing the audio it has received already and then send an EndOfTranscript message. This message is usually sent at the end of file or when the microphone input is stopped.
message: "EndOfStream"last_seq_no(Int): Required. The total number of audio chunks sent (in theAddAudiomessages).
EndOfTranscript
Sent from the API to the Client when the API has finished all the audio, as marked with the EndOfStream message. The API sends this only after it sends all the corresponding AddTranscript messages first. Upon receiving this message the Client can safely disconnect immediately because there will be no more messages coming from the API.
Supported audio types
An AudioType object always has one mandatory field type, and potentially more mandatory fields based on the value of type. The following types are supported:
type: "raw"
Raw audio samples, described by the following additional mandatory fields:
encoding(String): Encoding used to store individual audio samples. Currently supported values:pcm_f32le- Corresponds to 32 bit float PCM used in the WAV audio format, little-endian architecture. 4 bytes per sample.pcm_s16le- Corresponds to 16 bit signed integer PCM used in the WAV audio format, little-endian architecture. 2 bytes per sample.mulaw- Corresponds to 8 bit μ-law (mu-law) encoding. 1 byte per sample.
sample_rate(Int): Sample rate of the audio
Please ensure when sending raw audio samples in real-time that the samples are undivided. For example, if you are sending raw audio via pcm_f32le, the sample should always contain 4 bytes. Here, if a sample did not contain 4 bytes, and then an EndOfStream message were sent, this would then cause an error. Required byte sizes per sample for each type of raw audio are listed above.
type: "file"
Any audio/video format supported by GStreamer. The AddAudio messages have to provide all the file contents, including any headers. The file is usually not accepted all at once, but segmented into reasonably sized messages.
Example audio_format field value:
audio_format: {type: "raw", encoding: "pcm_s16le", sample_rate: 44100}
Transcription config
A TranscriptionConfig object specifies various configuration values for the recognition engine. All the values are optional, using default values when not provided.
language(String): Required. Language model to process the audio input, normally specified as an ISO language code e.g. 'en'.domain(String): Optional. Request a specialized language pack optimized for a particular domain, e.g. 'finance'. Domain is only supported for selected languages.additional_vocab(List:AdditionalWord): Optional. Configure additional words. See Additional words. Default is an empty list. You should be aware that there is a performance penalty (latency degradation and memory increase) from usingadditional_vocab, especially if you intend to load in a large word list. When initialising a session that usesadditional_vocabin the config you should expect a delay of up to 15 seconds, and an additional 800MB to 1700MB of memory (depending on the size of the list).diarization(String): Optional. The speaker diarization method to apply to the audio. The default is "none" indicating that no diarization will be performed. An alternative option is "speaker_change" diarization in which the ASR system will attempt to detect any changes in speaker. Speaker changes are indicated in the results using an object with atypeset tospeaker_change. Speaker change is a beta feature.enable_partials(Boolean): Optional. Whether or not to send partials (i.e.AddPartialTranscriptmessages) as well as finals (i.e.AddTranscriptmessages). The default isfalse.max_delay(Number): Optional. Maximum delay in seconds between receiving input audio and returning partial transcription results. The default is 10. The minimum and maximum values are 2 and 20.max_delay_mode(String): Optional. Allowed values arefixedandflexible. The default isflexible. Where an entity is detected when usingflexible, the latency of a transcript may exceed the threshold specified inmax_delayto allow recognition of entities to be more accurate. When usingfixed, the transcript will be returned in segments that will never exceed themax_delaythreshold even if this results in inaccuracies in entity recognition.output_locale(String): Optional. Configure output locale. See Output locale. Default is an empty string.punctuation_overrides(Object:PunctuationOverrides): Optional. Options for controlling punctuation in the output transcripts. See Punctuation overrides.speaker_change_sensitivity(Number): Optional.: Controls how responsive the system is for potential speaker changes. The value ranges between zero and one. High value indicates high sensitivity, i.e. prefer to indicate a speaker change if in doubt. The default is 0.4. This setting is only applicable when using"diarization": "speaker_change".operating_point(String): Optional. Which model within the language pack you wish to use for transcription with a choice betweenstandardandenhanced. See API How-to Guide for more detailsenable_entities(Boolean): Optional. Whether a user wishes for entities to be identified with additional spoken and written word format. Supported valuestrueorfalse. The default isfalse.
Requesting an enhanced model
Speechmatics supports two different models within each language pack; a standard or an enhanced model. The standard model is the faster of the two, whilst the enhanced model provides a higher accuracy, but a slower turnaround time.
The enhanced model is a premium model. Please contact your account manager or Speechmatics if you would like access to this feature.
An example of requesting the enhanced model is below
{
"message": "StartRecognition",
"audio_format": {
"type": "raw",
"encoding": "pcm_f32le",
"sample_rate": 16000
},
{
"transcription_config": {
"language": "en",
"operating_point": "enhanced"
}
}
Please note: standard, as well as being the default option, can also be explicitly requested with the operating_point parameter.
Additional words
Additional words expand the standard recognition dictionary with a list of words or phrases called additional words. An additional word can also be a phrase, as long as individual words in the phrase are separated by spaces. This is the custom dictionary supported in other Speechmatics products. A pronunciation of those words is generated automatically or based on a provided sounds_like field. This is intended for adding new words and phrases, such as domain-specific terms or proper names. Better results for domain-specific words that contain common words can be achieved by using phrases rather than individual words (such as action plan).
AdditionalWord is either a String (the additional word) or an Object. The object form was introduced in 0.7.0. The object form has the following fields:
content(String): The additional word.sounds_like(List:String): A list of words with similar pronunciation. Each word in this list is used as one alternative pronunciation for the additional word. These don't have to be real words - only their pronunciation matters. This list must not be empty. Words in the list must not contain whitespace characters. Whensounds_likeis used, the pronunciation automatically obtained from thecontentfield is not used.
The String form "word" corresponds with the following Object form: {"content": "word", "sounds_like": ["word"]}.
Full example of additional_vocab:
"additional_vocab": [
"speechmatics",
{"content": "gnocchi", "sounds_like": ["nyohki", "nokey", "nochi"]},
{"content": "CEO", "sounds_like": ["seeoh"]},
"financial crisis"
]
To clarify, the following ways of adding the word speechmatics are equivalent with all using the default pronunciation:
"additional_vocab": ["speechmatics"]"additional_vocab": [{"content": "speechmatics"}]"additional_vocab": [{"content": "speechmatics", "sounds_like": ["speechmatics"]}]
Output locale
Change the spellings of the transcription according to the output locale language code. If the selected language pack supports a different output locale, this config value can be used to provide spelling for the transcription in one of these locales. For example, the English language pack currently supports locales: en-GB, en-US and en-AU. The default value for output_locale is an empty string that means the transcription will use its default configuration (without spellings being altered in the transcription).
The following locales are supported for Chinese Mandarin. The default is simplified Mandarin.
- Simplified Mandarin (cmn-Hans)
- Traditional Mandarin (cmn-Hant)
Punctuation overrides
This object contains settings for configuring punctuation in the transcription output.
permitted_marks(List:String) Optional. The punctuation marks which the client is prepared to accept in transcription output, or the special value 'all' (the default). Unsupported marks are ignored. This value is used to guide the transcription process.sensitivity(Number) Optional. Ranges between zero and one. Higher values will produce more punctuation. The default is 0.5.
Error messages
Error messages have the following fields:
message: "Error"code(Int): Optional. A numerical code for the error. See below. TODO: This is not yet finalised.type(String): Required. A code for the error message. See the list of possible errors below.reason(String): Required. A human-readable reason for the error message.
Error types
type: "invalid_message"- The message received was not understood.
type: "invalid_model"- Unable to use the model for the recognition. This can happen if the language is not supported at all, or is not available for the user.
type: "invalid_config"- The config received contains some wrong/unsupported fields.
type: "invalid_audio_type"- Audio type is not supported, is deprecated, or the audio_type is malformed.
type: "invalid_output_format"- Output format is not supported, is deprecated, or the output_format is malformed.
type: "not_authorised"- User was not recognised, or the API key provided is not valid.
type: "insufficient_funds"- User doesn't have enough credits or any other reason preventing the user to be charged for the job properly.
type: "not_allowed"- User is not allowed to use this message (is not allowed to perform the action the message would invoke).
type: "job_error"- Unable to do any work on this job, the Worker might have timed out etc.
type: "data_error"- Unable to accept the data specified - usually because there is too much data being sent at once
type: "buffer_error"- Unable to fit the data in a corresponding buffer. This can happen for clients sending the input data faster then real-time.
type: "protocol_error"- Message received was syntactically correct, but could not be accepted due to protocol limitations. This is usually caused by messages sent in the wrong order.
type: "unknown_error"- An error that did not fit any of the types above.
Note that invalid_message, protocol_error and unknown_error can be triggered as a response to any type of messages.
The transcription is terminated and the connection is closed after any error.
Warning messages
Warning messages have the following fields:
message: "Warning"code(Int): Optional. A numerical code for the warning. See below. TODO: This is not yet finalised.type(String): Required. A code for the warning message. See the list of possible warnings below.reason(String): Required. A human-readable reason for the warning message.
Warning types
type: "duration_limit_exceeded"- The maximum allowed duration of a single utterance to process has been exceeded. Any AddAudio messages received that exceed this limit are confirmed with AudioAdded, but are ignored by the transcription engine. Exceeding the limit triggers the same mechanism as receiving an
EndOfStreammessage, so the Server will eventually send anEndOfTranscriptmessage and suspend. - It has the following extra field:
duration_limit(Number): The limit that was exceeded (in seconds).
- The maximum allowed duration of a single utterance to process has been exceeded. Any AddAudio messages received that exceed this limit are confirmed with AudioAdded, but are ignored by the transcription engine. Exceeding the limit triggers the same mechanism as receiving an
Info messages
Info messages denote additional information sent form the Server to the Client. Those are similar to Error and Warning messages in syntax, but don't actually denote any problem. The Client can safely ignore these messages or use them for additional client-side logging.
message: "Info"code(Int): Optional. A numerical code for the informational message. See below. TODO: This is not yet finalised.type(String): Required. A code for the info message. See the list of possible info messages below.reason(String): Required. A human-readable reason for the informational message.
Info message types
-
type: "recognition_quality"- Informs the client what particular quality-based model is used to handle the recognition.
- It has the following extra field:
quality(String): Quality-based model name. It is one of"telephony","broadcast". The model is selected automatically, for high-quality audio (12kHz+) the broadcast model is used, for lower quality audio the telephony model is used.
-
**
type: "model_redirect"- Informs the client that a deprecated language code has been specified, and will be handled with a different model. For example, if the
modelparameter is set to one of en-US, en-GB, or en-AU, then the request may be internally redirected to the Global English model (en).
- Informs the client that a deprecated language code has been specified, and will be handled with a different model. For example, if the
-
**
type: "deprecated"- Informs about using a feature that is going to be removed in a future release.
Example communication
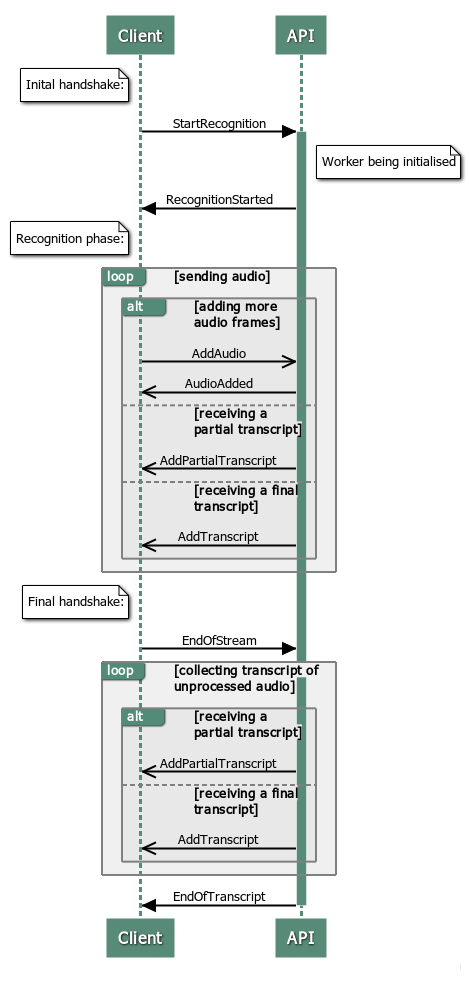
The communication consists of 3 stages - initialization, transcription and a disconnect handshake.
On initialization, the StartRecognition message is sent from the Client to the API and the Client must block and wait until it receives a RecognitionStarted message.
Afterwards, the transcription stage happens. The client keeps sending AddAudio messages. The API asynchronously replies with AudioAdded messages. The API also asynchronously sends AddPartialTranscript and AddTranscript messages.
Once the client doesn't want to send any more audio, the disconnect handshake is performed. The Client sends an EndOfStream message as it's last message. No more messages are handled by the API afterwards. The API processes whatever audio it has buffered at that point and sends all the AddTranscript and AddPartialTranscript messages accordingly. Once the API processes all the buffered audio, it sends an EndOfTranscript message and the Client can then safely disconnect.
Note: In the example below, -> denotes a message sent by the Client to the API, <- denotes a message send by the API to the Client. Any comments are denoted "[like this]".
-> {"message": "StartRecognition", "audio_format": {"type": "file"},
"transcription_config": {"language": "en", "enable_partials": true}}
<- {"message": "RecognitionStarted", "id": "807670e9-14af-4fa2-9e8f-5d525c22156e"}
-> "[binary message - AddAudio 1]"
-> "[binary message - AddAudio 2]"
<- {"message": "AudioAdded", "seq_no": 1}
<- {"message": "Info", "type": "recognition_quality", "quality": "broadcast", "reason": "Running recognition using a broadcast model quality."}
<- {"message": "AudioAdded", "seq_no": 2}
-> "[binary message - AddAudio 3]"
<- {"message": "AudioAdded", "seq_no": 3}
"[asynchronously received transcripts:]"
<- {"message": "AddPartialTranscript", "metadata": {"start_time": 0.0, "end_time": 0.5399999618530273, "transcript": "One"},
"results": [{"alternatives": [{"confidence": 0.0, "content": "One"}],
"start_time": 0.47999998927116394, "end_time": 0.5399999618530273, "type": "word"}
]}
<- {"message": "AddPartialTranscript", "metadata": {"start_time": 0.0, "end_time": 0.7498992613545260, "transcript": "One to"},
"results": [{"alternatives": [{"confidence": 0.0, "content": "One"}],
"start_time": 0.47999998927116394, "end_time": 0.5399999618530273, "type": "word"},
{"alternatives": [{"confidence": 0.0, "content": "to"}],
"start_time": 0.6091238623430891, "end_time": 0.7498992613545260, "type": "word"}
]}
<- {"message": "AddPartialTranscript", "metadata": {"start_time": 0.0, "end_time": 0.9488123643240011, "transcript": "One to three"},
"results": [{"alternatives": [{"confidence": 0.0, "content": "One"}],
"start_time": 0.47999998927116394, "end_time": 0.5399999618530273, "type": "word"},
{"alternatives": [{"confidence": 0.0, "content": "to"}],
"start_time": 0.6091238623430891, "end_time": 0.7498992613545260, "type": "word"}
{"alternatives": [{"confidence": 0.0, "content": "three"}],
"start_time": 0.8022338627780892, "end_time": 0.9488123643240011, "type": "word"}
]}
<- {"message": "AddTranscript", "metadata": {"start_time": 0.0, "end_time": 0.9488123643240011, "transcript": "One two three."},
"results": [{"alternatives": [{"confidence": 1.0, "content": "One"}],
"start_time": 0.47999998927116394, "end_time": 0.5399999618530273, "type": "word"},
{"alternatives": [{"confidence": 1.0, "content": "to"}],
"start_time": 0.6091238623430891, "end_time": 0.7498992613545260, "type": "word"}
{"alternatives": [{"confidence": 0.96, "content": "three"}],
"start_time": 0.8022338627780892, "end_time": 0.9488123643240011, "type": "word"}
{"alternatives": [{"confidence": 1.0, "content": "."}],
"start_time": 0.9488123643240011, "end_time": 0.9488123643240011, "type": "punctuation", "is_eos": true}
]}
"[closing handshake]"
-> {"message":"EndOfStream","last_seq_no":3}
<- {"message": "EndOfTranscript"}